
Most people, both in support and opposition to AI adoption, see the transformational power of the technology. I do as well. In hype cycles, it can be easy to get sucked into hyperbole and extreme predictions, and those opinions are often rewarded. At the same time, it can be easy to look at potential problems and leverage them to overlook positive developments. I am not interested in either of those. Instead, I am interested in answering the following:
- What useful results can I get from AI
- Where do I think AI can realistically go
Ultimately, there is a lot of uncertainty, so my predictions here shouldn't be taken as authoritative. With this in mind, I see a couple of core trends right now:
- People think the domain of what generative AI systems can do is much larger than what they actually can do well. At the same time, some of the ideas that came from Generative AI are of tremendous value, even outside of a Generative AI context.
- "More data" may not be enough to improve models materially, and they could require much more intentional engineering to gain more features. I think that LLMs should be primarily used for language tasks. AI generally should only be used when needed, not as a crutch for lazy engineering.
- The industry seems to be trending towards generalized amalgams. While there may be a space for this in the long term, I think there will still be demand for more specific and specialized systems.
- User experience has not been a major concern thus far. I think that user experience, not technical capability, will determine whether certain systems "win" the Generative AI war.
- As generative AI becomes cheaper to operate, industry economics will undergo unimaginable shifts. I expect the personalization era to follow the aggregation era of the last two decades. This will disrupt traditional business models, possibly more so than the aggregation era.
Current Uses for Generative AI
Generative AI seems powerful, but how are people using it? I see three categories:
- Communication/Transformation
- Simple Queries (Retrieval)
- Advanced Queries (Computation)
Communication/Transformation
The most straightforward use case for Generative AI is creation. That primarily means text and image generation, typically from a prompt. A prompt is fed in, and pattern matching occurs, filling in details to turn ideas into art or complete writing. This is the most promising use case. The models are designed for this purpose and generally do a good job.
This use can, however, hurt the effectiveness of communication because it adds content that wasn't in the prompt. Effective communication requires intentional choices to guide audience understanding. Generative AI adds additional details that weren't prompted. In the best-case scenario, this can make communication more time-consuming, but in some cases, it can also obscure intent or communicate unintended messages.
Example: Generative AI in Outlook
I have tried to incorporate generative AI into my life as an exercise in understanding where the technology is today. The best example I have found, at least in theory, is Microsoft Copilot in Outlook.
Outlook can do two things with AI: summarize email chains and generate responses. These are pure transformation tasks. Emails are expected to be professionally written, and the information is largely self-contained. Thus, an LLM should be perfect for the role.
I have tried to use "Reply with Copilot" several times and have usually left disappointed.
My process is as follows:
- Describe the tone that I want to reply to (and the role of the recipient)
- Outline the core points that I want to get across
- Generate an output
- Modify prompt and regenerate
- Manually modify to achieve my desired end product.
As expected, the writing follows grammatical patterns perfectly, with an AI trained to predict words. However, I usually delete most (if not all) of what was generated and write a manual reply. That grammatical perfection often obscures my core points with flowery (but irrelevant) surrounding language, poor ratios of ideas that further confuse intention, and undesirable tone.
I recently tried to use this process to write an email to a professor about a mistake in the grade book. I used Outlook on my phone, so generative AI would be convenient. I asked it to write an email (concisely with a tone that was casual but appropriate for an academic environment) that:
- Congratulated my professor on a recent accomplishment
- Asked him to review my grade on the assignment to see if it was a mistake
- Thanked him for his time and concluded by saying I would see him tomorrow.
If I had written this myself, I would have dedicated one sentence to points 1 and 3 and two to point 2. I would also have used tone intentionally to delicately balance professionalism with firmness. Copilot dedicated six sentences to point 1, one to point 2, and three to point 3. It was also too soft in its tone. It said that the promotion was related to his work as a professor, which was not true, though a reasonable extrapolation based on my prompt.
Technically, Copilot did nothing wrong here. I should've given more prompting to get a better result. However, I spent more time writing prompts than I eventually spent after deleting everything to write the message I wanted. The main point is that "good" writing does not necessarily mean effective writing.
Let's now imagine that the professor used a generative summary to read that email because of how long the message was. The AI likely would've focused primarily on the congratulations for the accomplishment and minimized or completely ignored the core point of my message.
This would've put the AI in a fascinating spot, where it was essentially the world's most expensive lossy compression algorithm that significantly expanded, rather than compressed, the message. I imagine this scenario is common in organizations that employ Microsoft Copilot at scale. That would lead to the inevitable question: is that a helpful technology? It probably offers social and professional benefits for everyone involved as individuals, but at the macro level, it would probably be better to focus on concise, effective writing.
Simple Queries
Integrations with services like Bing and Wolfram|Alpha have given LLMs new power. Now, they can predict language and use external data sources to provide more insightful responses. This has brought a meaningful paradigm shift in how people interact with information. Google shifted information from topics (e.g., a library index) to specific pages. ChatGPT can now synthesize web information to respond reasonably accurately to simple queries.
These external services were vital to reducing the hallucination problem. LLMs would answer user prompts convincingly and assertively but not truthfully. The responses were based on word prediction, so the grammatical structure would make it seem valid. This was particularly prevalent with more recent information not included in the model training dataset.
Simple queries are suitable for information retrieval. As an example, I recently asked ChatGPT for a basic summary of the relationship between the UAE's emirate (provincial) governments and the national government. This would likely require visiting several pages in order to understand, but there is enough information available online to get a good summary. It was presented in a way that was easy to understand. However, they struggle beyond reiterating content that has already been written.
Advanced Queries
What is 1 + 1? The answer is 2. There are plenty of places where this can be found online. Thus, an LLM likely has this answer encoded. How about 3837 x 14922? This problem has not been solved online before. I solved this problem using a calculator since I could not find the answer online. If you are curious, 3837 x 14922 = 57235714.
Except, that is not the answer. Before this post, a pure LLM's answer could be very unpredictable because it does not have a clear prediction pattern. Now, an LLM might give the wrong answer. This would mean I gave a wrong answer in this post, meaning that 57235714 would be the most likely value to follow 3837 x 14922 = compared to any other actual value.
Simple arithmetic is one of the most straightforward challenges for computers, yet LLMs struggle since they focus solely on language. If you ask ChatGPT 4, it will give you the correct answer. However, it will do that by generating a Python program that returns the value, running that program, and then passing that value back to the LLM. The LLM will then deal with the language task of returning the value to the user.
Many queries will run through these external processes. I call this approach "thin wall LLMs," where a user gets the impression that an LLM is doing more work while, in reality, it acts primarily as an interface to another system. Instead, the bulk of the work is done through external processing systems, including traditional machine learning algorithms. Even the Bing and Wolfram|Alpha integrations handle the bulk of processing outside of the LLM itself.
Artificial General Intelligence vs Thin Wall
Artificial General Intelligence (AGI) is widely considered the ultimate goal of generative AI. AGI is the idea that an LLM would be large and sophisticated enough to solve any prompt that a person could ask. As a leadership philosophy, I like the idea of setting AGI as a North Star for development orientation. I hope AGI is achieved. However, depending on the definition and specification of AGI, I am not highly confident that it can be achieved. I am also not confident that the investments required to head towards an AGI North Star is aligned with what enterprises need in the medium term.
At the very least, I do not think that "more data" alone will be enough to achieve any form of AGI. If we look of what would be required to have generic problem-solving AI, we would need:
- A way to reliably extract detailed intent from arbitrary input
- A way to segment any human action into a series of steps, with decisions taken throughout the process
- A way to model each of those steps in an executable environment (such as a Python compute environment)
- A way to reliably attribute and isolate changes in outcome to specific decisions made
- These steps need to be applied to any arbitrary domain, including novel ones, without significant documentation or engineering support
The problem space for these specifications is massive, and the engineering work is incalculable. These goals could be reached at some undetermined point in the future with an unpredictable amount of investment. As an automation engineer, there are too many uncertainties for me to gamble on reaching AGI. I need to focus on delivering organizational value faster, and I want AI tools to help me achieve these goals.
The problem becomes much less complex when people try to leverage AI to achieve specific goals. The more specific the goal, the better. Indeed, with a narrow enough problem, AI may not even be necessary. This is the principle behind the thin wall approach: AI should be used sparingly and as an intentional engineering decision, rather than as a panacea to all engineering problems. The wall refers to how significantly the outermost layer/interface of the system relies on AI. The thin walls may not always be the same "thickness:"
- It may be a matter of running the data through the same process, potentially including conditional execution
- It may involve the classification of entry into one of several problem processes that have pre-written steps
- It may involve determining the steps that need to be run arbitrarily, potentially based on AI predictions
As I examine how AI can help solve my problems, I am taking the thin-wall approach. I am intentionally using AI models only as large as necessary to achieve my goals. I have found that this leads to more efficient execution and lower costs.
Diminishing Returns on Language Models
Why is it unlikely for LLMs to be able to solve the generic problems? Fundamentally, the problem relies on the fact that they are, first and foremost, designed for language processing. We don't know what will happen as more data gets fed into LLMs. However, we are at the point where a large percentage of global knowledge is contained in these LLMs, and they still are ineffective (at least on their own) at analytical processing and logical inference.
LLMs will continue to grow with more data, but the amount of data left to train on is shrinking. Personally, much of the value that I get out of ChatGPT 4 comes from those external data sources, not from the LLM itself.
It is likely that as training comes from more obscure sources, the returns on core functionality will experience less benefit. I expect this will be particularly true given how critical code execution is to the intelligence of LLMs and breaking language patterns. OpenAI has already indexed nearly all publicly available source code, yet the problems that it can solve remain fairly simple.
Large models aren't necessarily bad, though. Why am I concerned about model size? I am worried about operational costs for LLMs. I expect that there will be some downward pressure on AI operational costs in the 2020s through cheaper semiconductors, greater competition, and the possibility of AI-specific integrated circuits. At the same time, I don't think we will see 1970s-1990s levels of improvement. Moore's law has generally held up to now, but given the challenges with mass-producing chips with 3nm processes (largely caused by the laws of physics), it doesn't seem like it can hold up forever. I also am not confident that quantum chips have an expedient path to general availability, so I suspect we will enter a period of relative semiconductor stagnation.
Smaller, specialized models (or even traditional programs) will help reduce operational costs. Right now, AI platforms are eating up a lot of operational costs to gain market share. Investors are willing to tolerate losses. Despite this, the platforms remain expensive, especially for enterprise scale.
I dread the day when investors begin to demand profitability from AI providers. Enterprises can afford to be lazy right now and offload a lot of work to LLMs. However, once/if investors demand a healthy profit margin, it could wreak havoc on organizations worldwide. We saw this pattern with the cloud. The cloud had a clear return on investment early on due to subsidization and scalability. However, in a period of stability, the value proposition for large enterprises is less clear. Strategic decisions now to deploy efficient solutions could save organizations in the future.
Generalization, Specification, Amalgamation, and Specialization
Hey Google,
what can you do?
This was the first question I asked my Google Home. Its answers included creating alarms, getting the weather, and playing music. "Cool," I thought. That seems like a great way to get started. Those are the only things I have ever done with my Google Home, which I've had for three years.
All software has tradeoffs. For the context of Generative AI, I want to focus on two axes: generalization/specification and aggregation/specialization. Generalization/specification is the set of potential inputs to an application. Is the UI tightly controlled or can you enter anything you want? Amalgamation/specialization is the set of potential capabilities in the software. Can it be used to solve a lot of problems or is it designed to solve a small subset of problems?
The Blank Box Problem and Prompt Engineering
An AGI is the ultimate generalized and amalgamated system. Many people assume that generalized and amalgamated systems are better than specified and specialized systems. However, there is demand for both, and a balance is needed.
Excel is a fantastic example of a generalizer/amalgamator. It is a blank sheet on which you can do whatever you want, and I consider it one of the most powerful applications ever written.
If amalgamated generalization was universally good, Excel should dominate business software. Yes, it plays a big role in the enterprise, but companies like Oracle, Salesforce, SAP, and Atlassian also play big roles. Your SAP ERP, Oracle HR system, Salesforce sales management, and Jira project management could all be replaced with Excel.
However, specialized solutions tailored to specific objectives offer value. Salesforce is ready to meet sales needs right out of the box. Users get the data they need, right where they need it. It could be replaced with Excel, but the work required is not worth it when more specialized software is available.
When you open up Excel, you are greeted with a blank sheet. What can you do with this? The answer is a lot, but it is hard to understand what you can do, much less how to achieve it. That flexibility came at a cost of usability, which is why you will often see Excel used in much simpler ways than it theoretically could be used for.
Generally speaking, amalgams will be more valuable to a broader audience. However, that level of generalization will often come with more difficult user experiences.
This is the start page for Gemini. The ChatGPT start page looks similar. This interface is very general. You can do a lot using the text box, and there aren't many constraints from an interface perspective. However, it isn't clear what Gemini is capable of doing. Furthermore, if you find yourself doing repeated tasks in the interface, it is an awful experience.
The amount of work to do certain repetitive tasks is far too high to be viable in the long term. My biggest complaint is with so-called prompt engineering. The way LLMs are currently structured; in order to get good results, you need to write highly specific instructions with certain syntax and structure.
This syntax consists of building blocks like keywords and statements that can help guide the LLM to perform what you would like it to. When a prompt does not give the desired output, you have to diagnose the issue and modify your prompt such that the output becomes what you want. This is essentially a programming language.
I don't think it is realistic to ask everyone to become a programmer, even if it is a very high-level programming language. Prompt engineering is needed because context and intent are unclear. In order for AI tools to enter mass adoption, they need to be better about adding context and intent on top of natural language queries to give the desired results.
The Problems with Chatbots
I understand why the applications are designed the way they are, but I don't think that chatbots are going to be the primary interface to AI systems in the future. There are three problems that I see with chatbots:
- The domain of possible inputs is infinite
- Text is not optimal to return to users
- It is easy to reach error conditions
This is not to say that I disagree entirely with chatbots. WebEx bots are one of the most incredible technologies I have seen in recent years, and if I were to start an organization today, I would embrace them heavily. They can be done well, especially when adaptive cards are used. At the same time, like all systems, they require intentional designs. Highly generic systems lack intentional design, and I think the lack of intentionality could severely hurt adoption.
The Domain of Possible Inputs is Infinite
The Google Assistant can do a lot of things. So, why do I only do a small number of things with it? As mentioned in previous sections, the lack of guidance makes it hard to discover the full set of capabilities of a system.
Even with Generative AI chat systems, I usually only use them for a small number of tasks. My most common tasks for them are:
- Quickly identifying information sources relevant to a topic
- Quickly outlining a document prior to reading
- Asking questions to enhance my understanding while reading a document
Given how powerful these tools are, my usage is very narrow. This is a problem inherent to a lot of generic interfaces, where the lack of guidance often means underutilized capabilities.
In an AI context, another problem is the lack of understanding of intent. For an AI to interpret a question written in natural language (without significant prompt engineering) it has to make assumptions about context and intent. What does a user actually mean when they ask for something? What specific response are they looking for?
Intent is much easier to interpret through traditionally defined user interfaces. If I click on a "more" button on an email, it is reasonable to assume that I want that email as context. This is one of the things that I like about Copilot for Outlook: it allows me (in theory) to provide less context to my response compared to if I generated a response in a third-party LLM like ChatGPT. I think that LLM-enabled features could be much more user-friendly if they were triggered through traditional application interfaces rather than the chat interfaces we have gotten used to.
Text is Not Optimal to Return to Users
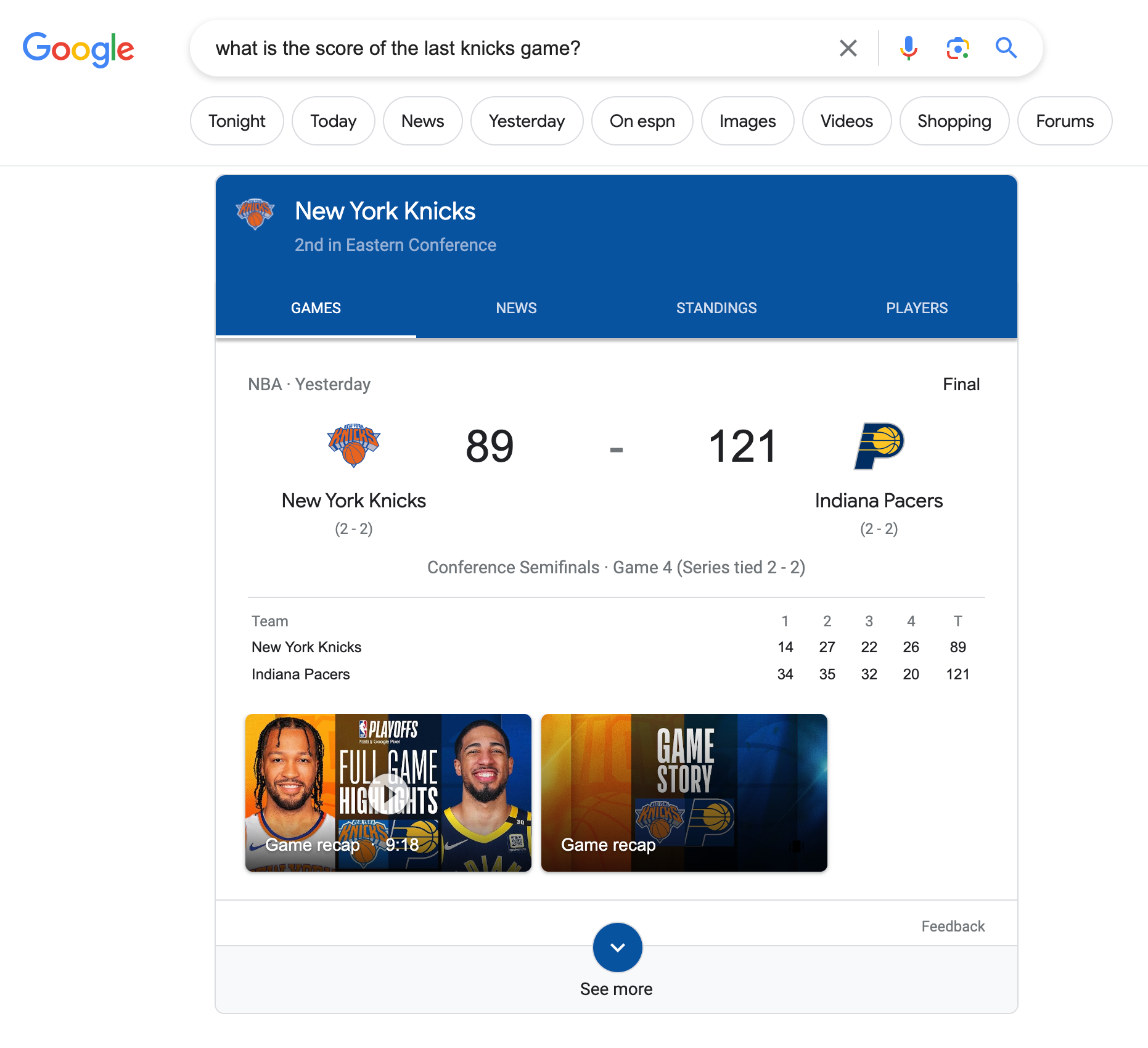
The second problem is that text is not optimal to return to users. This is something that Google has realized for a long time. Compare these two results for the questionWhat was the score of the last knicks game? from Gemini and ChatGPT

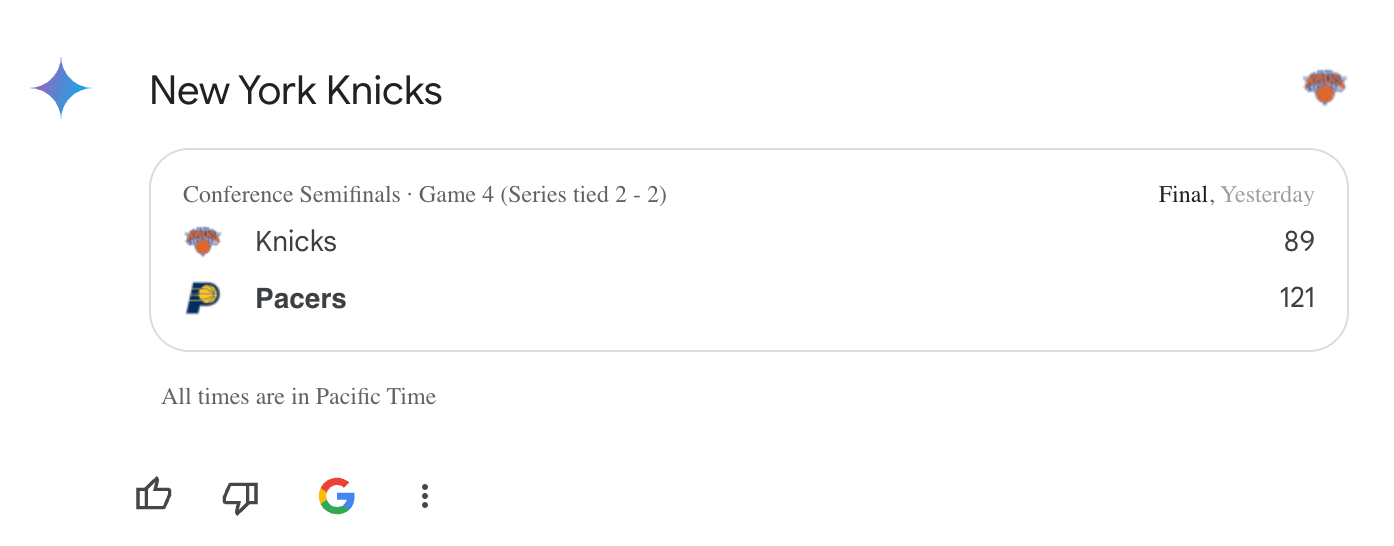
Gemini's response is much better, in large part thanks to Google's experience building interfaces on top of the search. It shows what I care about: the teams and the scores. ChatGPT, by contrast, uses a lot of language, obscuring what I care about, and also happens to use an older game score.
It's not just sports scores. When I built a chat bot for a NOC, I was super careful to design cards to present the most important information in the most visible spots. It is much easier to design cards around specific workflows than highly generalized systems.
It is Easy to Reach Error Conditions
A domain of infinite inputs makes it easy to reach error conditions. How many times have you asked a question to the Google Assistant, Siri, or Alexa and had it reply, "I'm sorry, I cannot do that." If you use any of those assistants on a regular basis, you have likely encountered those error states.
The LLMs will generally enter what I call "invisible error states." As opposed to returning an error when it cannot answer a question, it will instead return a best guess. This can be good, as it is less frustrating to users, but it also means that the output cannot be trusted. Some of the reviews of the Humane AI Pin and Rabbit R1 both suffer from these invisible states, for example, responding as if it is shutting down without actually shutting down.
These invisible error states can also come across as hallucinations. Earlier versions of ChatGPT were well known to create studies out of thin air. This meant that the responses from ChatGPT had to be carefully double-checked. ChatGPT does not have any understanding of truth, so there are no internal signals it can have to indicate that an error has occurred. Therefore, the output can never be fully trusted.
With a lot of the early hype around using ChatGPT for highly complex tasks (like building investment strategies), people assumed that the response was good even though the AI had no concept and merely performed word prediction. Ironically, I think that these invisible error states are why tools like ChatGPT are seen as so much better than older apps like Siri. ChatGPT gave more convincing responses than Siri, even if, at the time, Siri had more real-time information.
Predictions
If AGI can be achieved (or at least close to it), I think there will be some usage in highly generic systems. However, I think there will still be a market for domain-specific applications. The interface required for a highly generic system will just not be as good as domain-specific interfaces.
Outside of a hypothetical AGI world, I think that most enterprises would benefit from a careful balance of the four factors with an emphasis on being as specific and specialized as reasonable. The engineering work is far more manageable when systems are more constrained, and the utility of these highly generic systems is unclear.
The "throw a chatbot on it" approach that many applications, including much of the Microsoft suite, are taking doesn't seem like a very good idea in the long run. I think that approach will be phased out in exchange for more intentional user experience choices. This likely would include trying to establish as much of an understanding of user intention and context as possible before presenting a generative AI interface.
Critical Questions and Predictions
Looking to the future, there are a lot of questions that could change how the technology evolves. A lot of my thoughts in this article are hypotheticals, and nobody really knows how this will pan out long term.
The Impact of Data
The first important question is how the data volume will impact the system's effectiveness. If an AI model has entirely human language stored, can it be as smart as a human?
I think there may be a ceiling on how far language can go without other engineering work. I am also worried that the data that has not been added to models yet will be less relevant to core functionality, meaning that models will become much larger and more expensive with less direct impact on the vast majority of use cases.
Asymptotic Production
Either through AGI or more carefully scoped applications, AI will likely significantly impact traditional business models. Traditional business guidance would suggest that reducing marginal distribution costs would be good for business and lead to greater profit. However, as marginal distribution costs approached zero, unforeseen consequences occurred. People became less willing to pay for individual products.
For example, when CDs brought marginal distribution costs, people were generally willing to pay for CDs. However, as CDs turned to Internet distribution, piracy became rampant, and people were far less willing to pay for songs on iTunes. That led to the creation of aggregation services like Spotify.
The question brought by AI will be what happens as production costs and times approach zero. I suspect that the impact will be far greater than internet distribution (which itself has transformed nearly every industry it has touched). I suspect that digital products will lose much of their intrinsic value, and value will come from both aggregation and heavy personalization. TikTok, which essentially is a personal TV feed, is a model for what could happen to other industries.
I think that we could see a shift away from value being created through aggregation to value being created through personalization. The internet destroyed the value of music, meaning that only music repositories with every song became valuable (i.e. Spotify). In a world of infinite production, the value would be removed from the aggregator and to the personalizer: whichever company can have a radio station designed just for you, that not only uses songs that were already written but can create highly tailored new ones.
Is This Another Blockchain?
There are some similarities between AI/Generative AI and Blockchain. Both are incredibly expensive to operate and offer many hypothetical benefits, but the practical implications of such a technology are difficult to see. Blockchain ended up a colossal failure. Will AI/Generative AI live up to its promises?
I definitely don't see Machine Learning broadly as another Blockchain, and I don't even see generative AI as necessarily another Blockchain. Blockchain had a couple of factors that made it particularly ineffective at scale:
- Nearly all of its practical benefit was in facilitating crime
- It worked against traditional understandings of market economics by becoming more expensive as it became more widely used. It was explicitly designed to be as inefficient and expensive as possible
- The technology was heavily correlated to finances, meaning that it largely acted as a tool to circumvent financial regulation
- The technology had well over a decade to show any practical benefit, yet failed to, before entering mass adoption
At the same time, some parts of Blockchain could be valuable in the future. Cryptographically verifiable linked lists and distributed consensus algorithms, innovations that were tightly integrated with Blockchain, could provide value to software outside of a Blockchain context.
I see many good ideas in generative AI that could be applied to other contexts. I am working on a project right now that uses word vectorization to try to model relationships between arbitrary data entities. Strong natural language processing and more human text generation have a lot of value.
Machine learning has also repeatedly proven itself and entered products. Much of what we use today, from personalized ads to weather prediction and factory robotics, relies on machine learning. It is everywhere but was largely treated as an implementation detail out of the eyes of the general public. Thus, the technology has a proven track record, suggesting that there could be more practical benefits in the future.
Does the First Mover Advantage Matter?
While I think that the technology is transformational, I also think that some of the hyper-optimism should be tempered. I am not hugely concerned that Apple hasn't already built generative AI tooling into its phones, though that is widely rumored for the near future. We are still in the early stages of the technology, and while some first-mover advantage may have been established, I don't think it will be sustained.
There is a really obvious blind spot with the current leaders: OpenAI, Google, Anthropic, and more. They all seem to believe that technical supremacy will lead to success. Technical capability absolutely matters, but the productization stage is where I could see them falter.
Companies are going to figure out, through experimentation, how to take this technology and turn it into real, meaningful products. The current interfaces are really rudimentary, even when integrated into other products, but at least experimentation is happening. That being said, the experimentation that would turn this cool technology into something viable is not being driven by the current leaders.
I do not have confidence that OpenAI and Anthropic, or others can actually turn this technology into a meaningful product. OpenAI and Anthropic are too research-heavy, and Google has an atrocious history of productizing its research. That is what I think is most exciting about the Apple partnership: having a company that can really think about experience delivery. Apple was far from the first entrant into the smartphone/PDA market, but it made the experience that captured the market. Right now, we are in the equivalent of the era when Softbank and Docomo dominated smartphones. Yet, that era eventually passed to who would be the long-term leaders of the smartphone market.
I think that Microsoft and Apple are going to be the biggest winners. Notice: neither of them is particularly a leader in internally trained models. However, both of them know how to turn technology into products, and crucially, they have a lot of relevant data. If the trend of AI is towards personalization, then the moat for this technology is not all of the information in the world. Instead, it is the information that is relevant to the user. Apple holds that for many consumers, and Microsoft holds that for the enterprise. Google also stands to be a winner if they can successfully productize since they have both a strong understanding of global information and personal information.
How Far Will Costs Come Down?
I addressed the cost problem in the section about diminishing returns. However, I wanted to reiterate it here as well. The degree to which generative AI can be used and the degree to which AI can generalize problems versus needing heavy human engineering and intervention will hinge greatly on operational costs. This means the cost of the hardware to train datasets, the cost to get data to train on, and the cost to run inference on trained models.
I don't think that we will see the level of cost reductions seen in the PC era. Chips are already highly efficient and on the border of reaching limitations from the laws of physics. Models continue to grow, investors subsidize operations, and training is constrained by GPU availability.
If the costs come down significantly, then adoption will be much easier to justify. However, that will likely require AI-dedicated integrated circuits. The higher the costs and for longer, the more pressure there will be to look at alternate solutions. This may be "thin wall" AIs (see above) or even more traditional statistical analysis.
Right now the costs can be tolerated, but that cannot last forever. Many people think that if AGI can be reached, it will automatically be a good investment. While there certainly would be a value proposition, if the cost is too prohibitive, it could still push adoption away. Even more likely would be that the operational costs become an impediment to reaching AGI, regardless of whether AGI could theoretically be achieved.